
用正则久矣,一直想出一篇这方面的笔记,用来记录重难点。
博客重度参考慕课教程JavaScript正则表达式
regexper.com
这是一个很好的正则网址,此网不会用,可能显得不上档次?regexper.com,这个网址如果受外网限制不好访问的话,也可通过npm安装到本地访问,具体谷歌或看上面的慕课教程。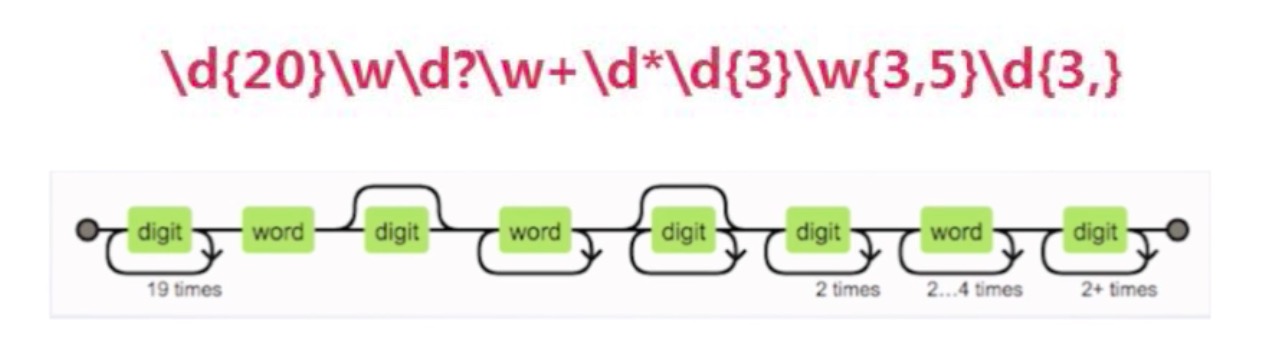
m 多行搜索
修饰符
正则有如下修饰符1
2
3g:global 全文搜索 不添加只搜索第一个匹配即停止
i : ignore case 忽略大小写 默认是大小写敏感
m: multiple lines 多行搜索
demo
使用多行修饰符后,就可以匹配每一行的^开头字符。
元字符
\t tab
此符号,在mac下按下一个tab键,使用下面表达式不成立,在有些电脑上又可以,目前尚不知原因。1
/\t/.test(' ')
字符类 的概念
- 我们可以使用元字符[]来构建一个简单类;
- 所谓类是指符合某些特性的对象,一个泛指,而不是特指某个字符
- 表达式[abc]把字符a或b或c归为一类,表达式可以匹配这类字符。
字符类取反
- 使用元字符^创建 反向类/负向类
- 反向类的意思是不属于某类的内容
- 表达式[^abc]表示 不是字符a或b或c的内容;
- 与 范围类
常见范围类 [a-zA-Z]
如上,它们通过-来拼接一个范围类;
下面的形式通常可以表示一个范围类:1
字符-字符
假如前后字符为 0、9,a、z;那么就被识别,构成一个常见的范围类;
因此当-位于两个字符之间时,如果两个字符可以被识别,那么此-具有特殊意义,表示范围类的意思;
如果不是位于两个字符之间,-匹配自身-;
-位于两个字符之间时的特殊意义
见上面的说明。
预定义类
既然[0-9]表示范围类,正则使用预定义类来预先规定好逻辑直接表示这个范围类,下面是常见预定义类: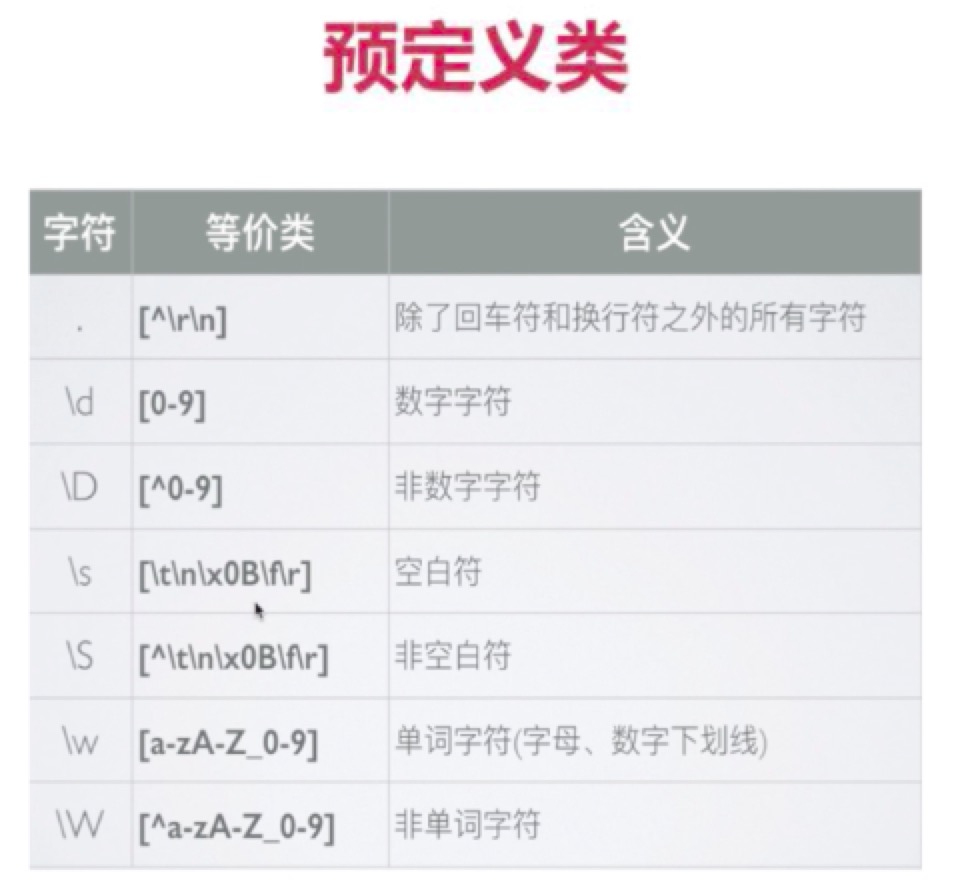
贪婪\非贪婪模式
贪婪模式(默认)
如下,正则可以匹配3到6个,默认情况下正则匹配最大数6,是为贪婪模式。1
'12345678'.replace(/\d{3,6}/g,'X') //X78
量词后加?变成非贪婪模式
非贪婪模式指可以匹配3到6个时,指匹配最小值3,{3,6}是量词:1
'12345678'.replace(/\d{3,6}?/g,'X') //XX78
分组与或
概述
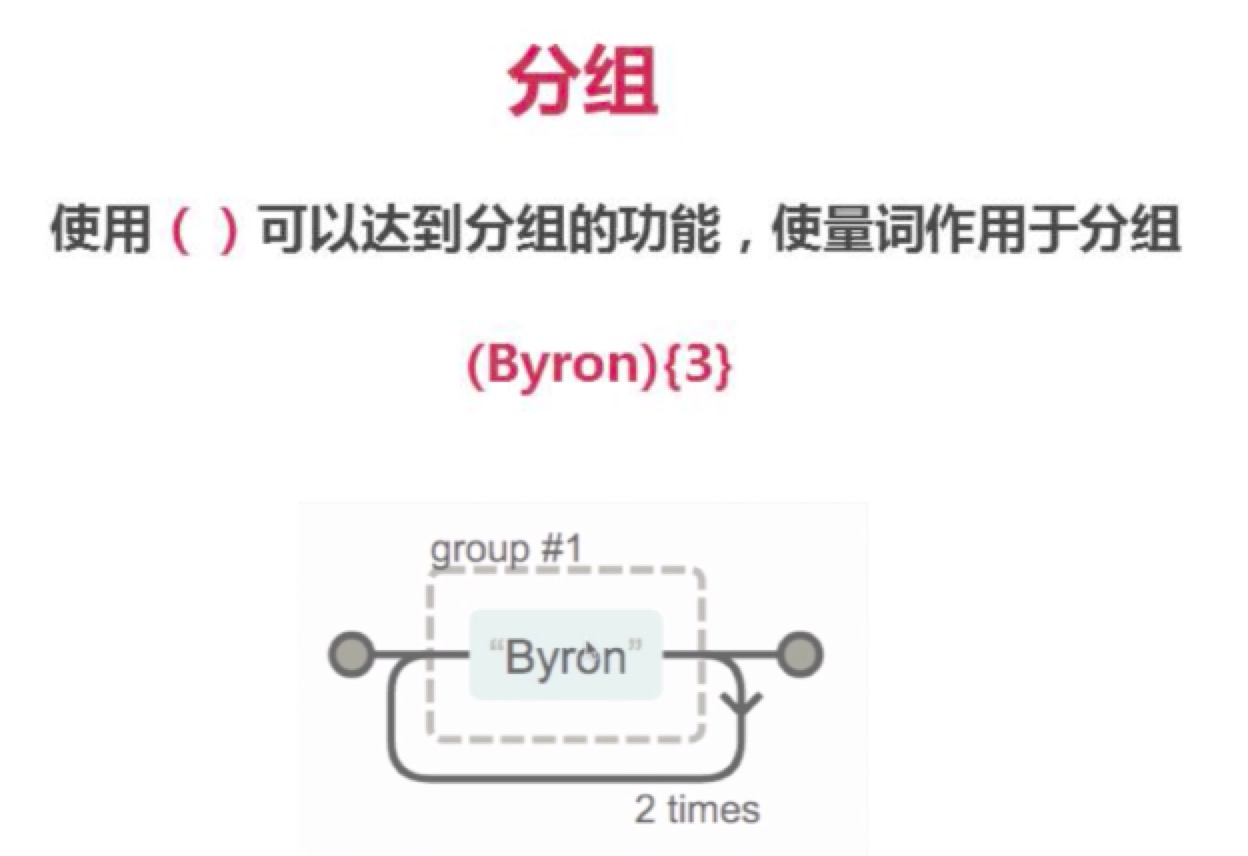
忽略分组 (?:)

更多知识参考 《关于 忽略分组 (?:)》
或与分组
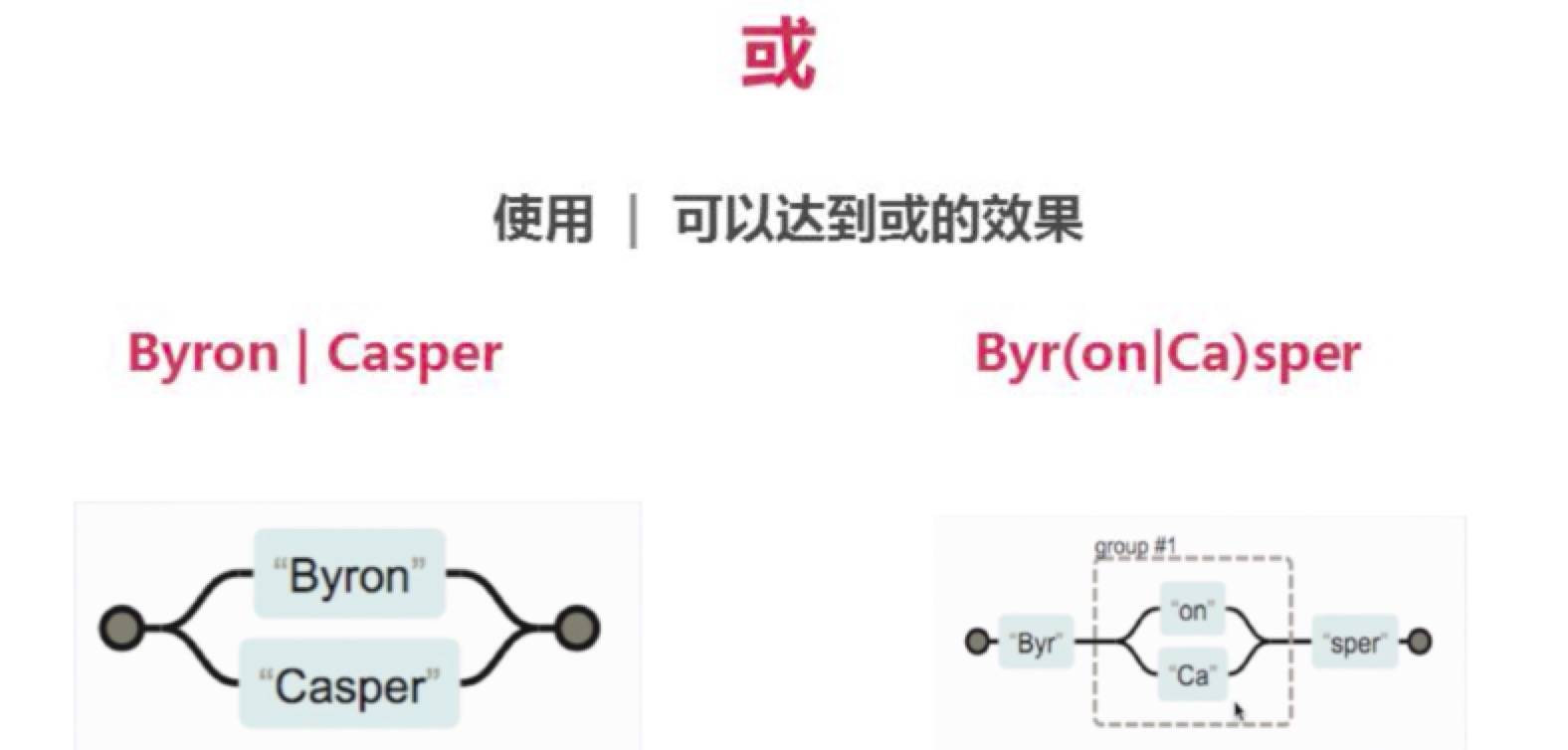
或的边界值理解
参考下面的 《|或的使用》
关于 忽略分组 (?:)
分组与忽略的妙用一
1 | var str = 'ppp; %24CC_test_session=AC_yyyy999;tianruoyouqing' |
上面正则中 (?:^|; ) 我必须要用到或,而这个或只用于判断 ^ 与 ; 两种情况,此时就用小括号分组一下
但是,我又希望这个分组不要用于分割返回结果,此时用 忽略分组 (?:),
前瞻
概述
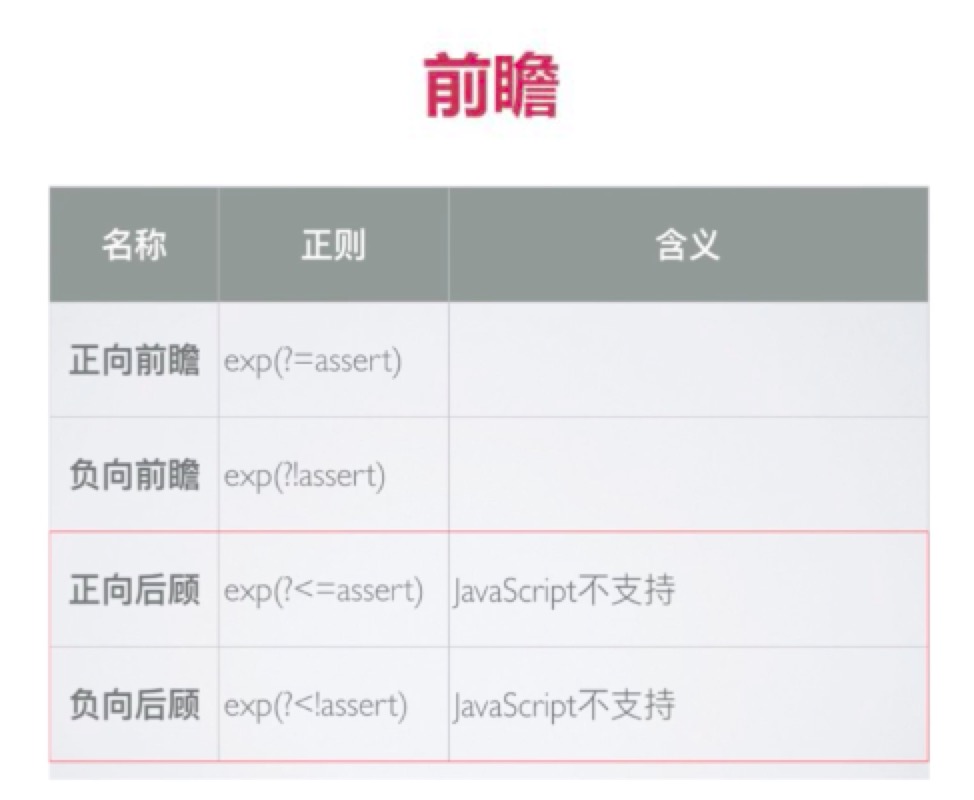
1 | 'a2*aa'.replace(/\w(?=\d)/,'H') //正向前瞻 "H2*aa"单词字符后面是数字的 |
断言
如上图片里面的 assert就是断言,断言是一个表达式,可运用与 正向前瞻和后向前瞻。
正向与负向的难理解性
刚开始听到正向负向会理解成其他意思,其实就是后面匹配断言assert与匹配相反的断言assert;
也可以说成是后面匹配断言的正向表达意思,和匹配 断言的负向(相反方向)的表达意思;
正向前瞻?=
参考上面概述
负向前瞻?!
参考上面概述
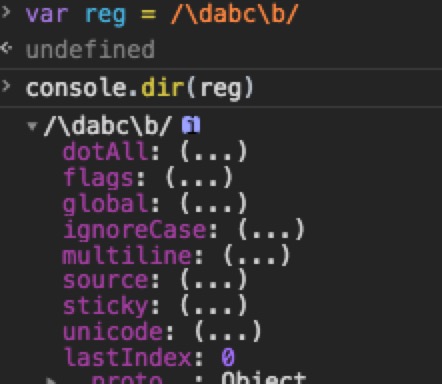
正则式的对象性
每一个正则式都是一个对象( new RegExp() ),因此都具有如下属性。
- global:是否全文搜索,默认false
- ignore case:是否大小写敏感,默认是false
- multiline:多行搜索,默认值是false
- lastIndex:当前表达式匹配内容的最后一个字符的下一个位置
- source:正则表达式的文本字符串
子表达式
子表达式为正则内的分组,如下有两个子表达式(\w)与(abc)1
var reg4 = /\d(\w)(abc)\d/g;
lastIndex让你怀疑人生
test的现象
1 | //每次执行下面代码都是对的 |
1 | //每次执行下面代码都是对的 |
每次test后正则式的lastIndex改变
如下,reg不仅是正则式,而且是对象,每执行完一次test,都会让reg的lastIndex发生变化,从而在下次匹配时有所不同,产生了不同结果。
每一次匹配成功后lastIndex会得到一个非零值,当匹配失败后,lastIndex值将置为零。1
2
3
4
5
6//每次执行下面代码都是对的
var reg = /\w/g; //reg.lastIndex=0
reg.test('a') //true //reg.lastIndex=1
reg.test('a') //false //reg.lastIndex=1 --> reg.lastIndex=0
reg.test('a') //true //reg.lastIndex=1
reg.test('a') //false //reg.lastIndex=1 --> reg.lastIndex=0
目前只发现在全局g的正则存在此现象
如上,目前只存在于g的正则式,非全局尚未发现此现象。因为非全局的lastIndex值都是0,而0有两成意思:第一 从0位置开始匹配;第二 lastIndex无效;所以在非全局下lastIndex可能无效(待考证)
非全局下lastIndex无效?
参考上面分析。
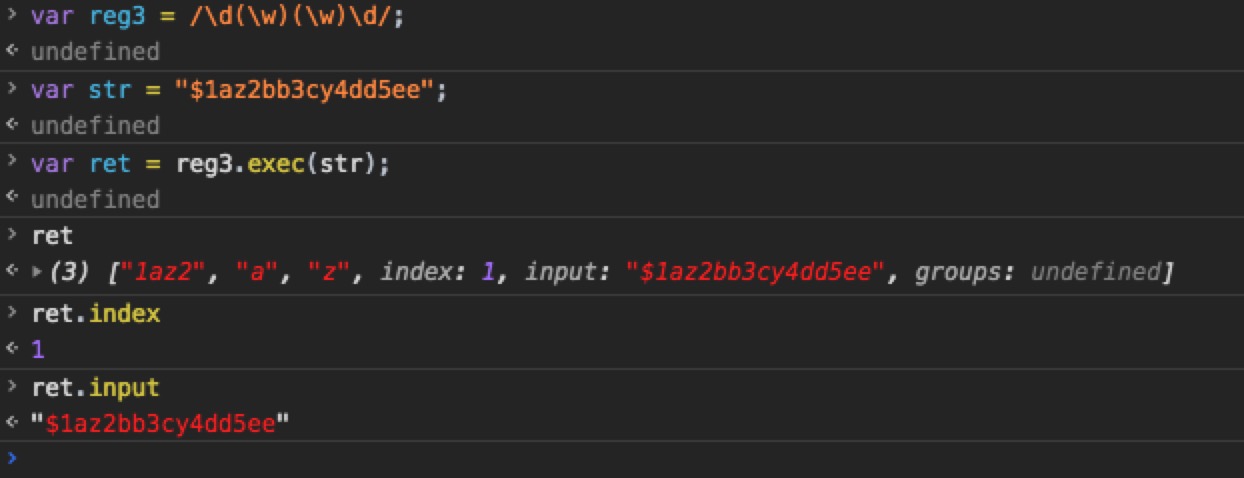
exec也有此现象
exec也有此现象,其他方法可能还有此现象,原因同test方法一样分析:1
2
3
4
5//每次exec执行的结果不一样
var reg4 = /\d(\w)(\w)\d/g;
var str = "$1az2bb3cy4dd5ee";
reg4.exec(str) //["1az2", "a", "z"] //index: 1
reg4.exec(str) //["3cy4", "c", "y"] //index: 7
解决方法
每次匹配前,手动地把lastIndex属性重置为0。
lastIndex为0的双重意思
参考《目前只发现在全局g的正则存在此现象》
exec
概述
在非全局匹配模式下,此函数的作用和match()函数是一样的,只能够在字符串中匹配一次,如果没有找到匹配的字符串,那么返回null,否则将返回一个数组。
子表达式
参考《子表达式》
返回数组内容
- 数组的第0个元素存储的是匹配字符串
- 第1个元素存放的是第一个引用型分组(子表达式)匹配的字符串,
- 第2个元素存放的是第二个引用型分组(子表达式)匹配的字符串,依次类推。
返回数组属性
返回数组还包括两个对象属性, - index属性声明的是匹配字符串的起始字符在要匹配的完整字符串中的位置,
- input属性声明的是对要匹配的完整字符串的引用。
match
是否全局影响很大
match()方法将检索字符串,以找到一个或多个与regexp匹配的文本
regexp是否具有标志g对结果影响很大
非全局模式
如果regexp没有标志g,那么match()方法就只能在字符串中执行一次匹配,没找到任何匹配文本将返回null,否则将返回一个数组,数组存放了与它找到的匹配文本有关的信息
返回数组内容与exec的一致,请参考《exec – 返回数组内容》《exec – 返回数组属性》1
2
3var reg4 = /\d(\w)(\w)\d/;
var str = "$1az2bb3cy4dd5ee";
str.match(reg3) //["1az2", "a", "z"] //index: 1 input: "$1az2bb3cy4dd5ee"
全局模式
如果regexp具有标志g则match()方法将执行全局检索,找到字符串中的所有匹配子字符串:没有找到任何匹配的子穿,则返回null,
否则返回一个数组,数组元素中存放的是字符串中所有匹配子串,而且也没有index属性或input属性1
2
3var reg4 = /\d(\w)(\w)\d/g;
var str = "$1az2bb3cy4dd5ee";
str.match(reg3) //["1az2", "3cy4"]
match与exec异同
在非全局下 二者结果相同
1 | var reg4 = /\d(\w)(\w)\d/; |
在全局下,有差别
全局下,exec返回的结果格式与非全局下一样;但match却只返回匹配的文本,不再返回子表达式信息。
其他
\s匹配空白而不仅仅空格
以下都成立:1
2
3
4/\s/.test('\n')
/\s/.test('\r') //回车
/\s/.test(' ')
/\s/.test('\xA0') //\xA0就是
常见元字符
split(reg)
除了字符串,也可以使用正则来split。1
'1b3c4d'.split(/\d/) //["", "b", "c", "d"]
多个正则合并使用
限制只能输入3位小数点:
这个例子也是或|的经典应用1
/^[1-9][0-9]*\.[0-9]{0,3}$|^[1-9][0-9]*$|^0\.?$|^0\.[0-9]{0,3}$/;
合并前:1
2
3
4/^[1-9][0-9]*\.[0-9]{0,3}$/.test(str)
/^[1-9][0-9]*$/.test(str)
/^0\.?$/.test(str)
/^0\.[0-9]{0,3}$/.test(str)
|或的使用
通过本篇的几个有关或的示例看出,
要理解或,最关键的是要理解 或的边界如何确定,
只要理解了或的边界了,那么问题就很好分析了,
或的边界
- 应该是 下一个|,
- 如果没有 就是最近的一个 分组符合
(, - 如果没有就是所有字符,
比如:1
2
3/rr|123|abc/ //边界下一个|
/rr(123|abc)/ //边界 最近的一个 分组符合`(`
/123111|abcttt/ //边界 如果没有就是所有字符
参考《多个正则合并使用》
示例二:
| 在 replace上的运用:
1 | var url = '/test/good/detail' |
demo
密码
本例是?!的经典应用
要求: 8~32位字符,字母、数字、特殊字符任意三种组成,特殊字符为!@#$%^&*()_+-=1
/^(?![a-zA-z]+$)(?!\d+$)(?![!@#$%^&*=\-\+\(\)\_]+$)(?![a-zA-z\d]+$)(?![a-zA-z!@#$%^&*=\-\+\(\)\_]+$)(?![\d!@#$%^&*=\-\+\(\)\_]+$)[a-zA-Z\d!@#$%^&*=\-\+\(\)\_]{8,32}$/
这个表达式先看最右侧[a-zA-Z\d!@#$%^&*=\-\+\(\)\_]{8,32}这是一个全匹配,然后利用剔除法,一个个剔除以下情况:
- 全是字母
(?![a-zA-z]+$) - 全是数字
(?!\d+$) - 全是特殊字符
(?![!@#$%^&*=\-\+\(\)\_]+$) - 字母与数字
(?![a-zA-z\d]+$)
等等。
剔除到最后,就只剩下一种情况,字母、数字、特殊字符任意三种组成。
注意的是,这几个特殊字符中这几个()_+-=,要带反斜杠转义,否则就会出问题,比如特殊字符 不包括,;等这些,也会被错误匹配
参考
千分位 与 $&
注意 ?: 的妙用
1 | function thousandth(str) { |
千分位的思路应该是,不管小数点后面的东西,只管小数点左侧的,或者完全没有小数点,只关注整数:
比如:
1234.01 ,我们只想找到上面左侧的1,然后在其后加 ‘,’;
12345.01 ,我们只想找到2,然后在其后加 ‘,’;
1234567.01 ,我们只想找到4和1,然后在其后加 ‘,’;
要想找到以上的左侧想要的1 或 2 或 4 1,其实就是基于其右侧的条件决定,
这就决定了需要配合断言;
那么我们要找的数字 就是 \d;
简单的断言就是 (?=\d{3});
但 只要3的倍数都可以,因此可以写成:(?=(\d{3})+)
要想将一个表达式作为一个整体,最好使用 ?: ,这样符合正则的阅读习惯,因此写成 (?=(?:\d{3})+)
数字可能直接以此结尾,也可能是小数点,因此可写成 (.\d+|$)
为了装逼也好,还是符合正则的阅读习惯,将(.\d+|$) 连成一个表达式,我们就加一个?:,因此成了 (?:.\d+|$)
整体连起来就是:str.replace(/\d(?=(?:\d{3})+(.\d+|$))/g, ‘$&,’)
附:
关于$&的解释
参考https://stackoverflow.com/questions/34510746/difference-between-1-and-in-regular-expressions1
The $& is a backreference to the whole match, while $1 is a backreference to the submatch captured with capturing group 1.
(?:x)[https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Guide/Regular_Expressions] :
匹配 ‘x’ 但是不记住匹配项。这种括号叫作非捕获括号,使得你能够定义与正则表达式运算符一起使用的子表达式。
看看这个例子 /(?:foo){1,2}/。
如果表达式是 /foo{1,2}/,{1,2} 将只应用于 ‘foo’ 的最后一个字符 ‘o’。
如果使用非捕获括号,则 {1,2} 会应用于整个 ‘foo’ 单词。
更多信息,可以参阅下文的 Using parentheses 条目.