html协议基础
5层网络模型
介绍
如图,我们只需理解应用层与传输层的作用,其他三层,知道就行。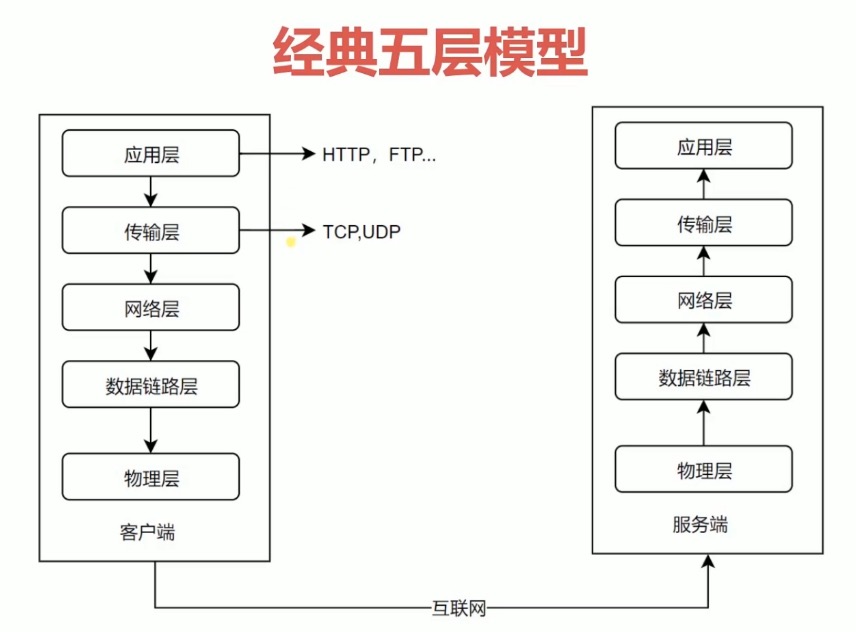
传输层
- 向用户提供可靠的端到端(end-to-end)服务;
- 传输层向高层屏蔽了下层数据通信的细节(比如一个post请求,如何分片如何发送使服务端很好接收到,这个规则由传输层实现,应用层的HTTP不用关心这些,但是适当理解对HTTP更好地使用是很有帮助的)。
应用层
- 为应用软件提供了很多服务;
- 帮我们实现了HTTP协议,我们只要按照规则去使用HTTP协议;
- 它构建于TCP协议之上;屏蔽了网络传输相关细节。
HTTP协议的发展历史
http/0.9
- 只有get
- 么有header等描述信息
- 服务器发送完毕,就关闭tcp连接
http/1.0
- 增加很多方式如 post put。。。
- 增加 status code 和 header
- 缓存、权限等
http/1.1 (当前的http协议)
- 持久连接
- pipeline
- 增加host和其他命令
http2 (还未普及)
- 所有数据以二进制传输
- 同一个连接里面发送多个请求不再需要按顺序来
- 头信息压缩以及后端主动推送等功能
关于头信息压缩:
在http1中,头信息如 Content-Type等,都是以字符串的形式保存,这些都比较占带宽;
在http2中,对头信息进行压缩,从而减少对带宽的占用。
关于 主动推送:
在http1中,向后台发送一个html请求,前台获得html后,经过浏览器解析,再次向后台发起css或js的请求;
http2中,向后台发起一个页面请求时,后台会将html和html内的css js 主动一次性推送给浏览器,提高性能。
tcp三次握手
如图,tcp三次握手,主要是解决客户端与服务端相隔很多远,通过光纤传输,容易出现延时和连接中断等问题;
第一次握手:客户端发消息给服务端,申请建立tcp连接;
第二次握手:客户端接收请求后,新建端口,用于tcp连接,并且向客户端发消息,验证客户端是否能正常接收来自客户端的消息;
第三次握手:客户端向服务端发消息说,我能正常接收到你那边发来的消息,你就放心的建立tcp连接吧。服务端接收到此消息后,建立tcp连接成功。
进一步解释下:
第一次握手,验证服务端能正常接收到客户端消息;
第二次握手,验证客服端能正常接收到服务端消息;
一来一往,两边都能接收到双方消息;
第三次握手,直接与服务端建立tcp连接。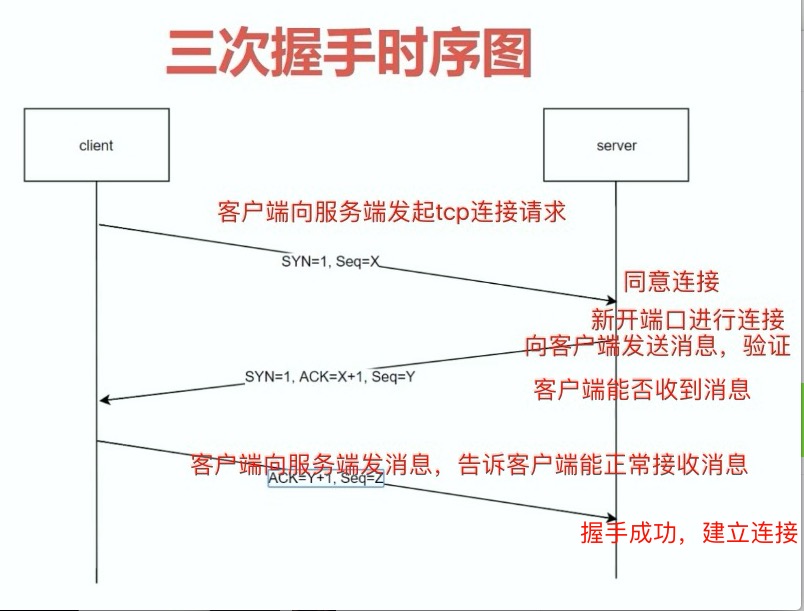
uri url urn
uri 包含 url 和 urn;uri与url一样用来定位资源地址。
url上的哈希值 起到锚点作用
#号后的哈希值,用来给前端渲染用,起到一个锚点作用,比如在mokedown文档博客总,通过#跳转到某个章节。1
http://127.0.0.1:4000/2019/05/21/koa2#chapter1
http 报文
图解
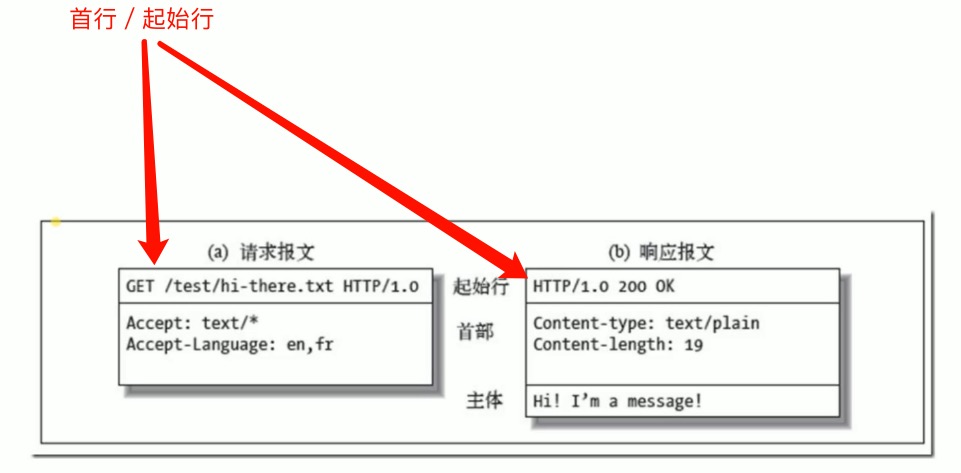
首行/起始行
首行里面是一些请求头以外的信息,上图中,请求的首行上定义了http的版本,method;
响应头包含了状态码等消息。
首行也是下面的矩形框内的 General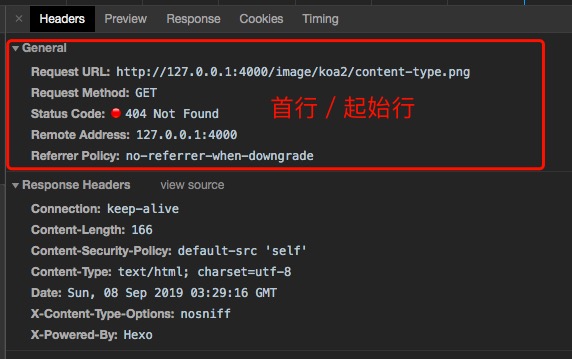
请求header/响应header
参考上图
跨域
认识跨域
跨域纯属浏览器端做的限制,请求是否跨域不影响浏览器是否将其发送到后台,浏览器都会将请求发送到后台,无论跨域与否。
服务器,无论跨域与否,都会正常将响应数据发送给浏览器。
浏览器接收到服务器的响应数据时,不同的是,浏览器对于跨域请求,
会读取响应数据的参数 Access-Control-Allow-Origin;
如果没有此参数,或此参数不允许客户端页面的host,那么浏览器将不会将响应的数据显示出来,并且抛异常不允许跨域。
浏览器并非不发送跨域请求
参考上面《认识跨域》
跨域是浏览器做的限制
跨域只是浏览器做的限制,其他客户端都不做跨域限制,比如git bash上运行 curl,服务器端给服务器发请求等等,都不会屏蔽跨域数据。
跨域是浏览器根据Access-Control-Allow-xxx做的限制
跨域与否,几乎只于 与后台设置的Access-Control-Allow-xxx值有关,浏览器只是根据 Access-Control-Allow-xxx的值,决定是否屏蔽响应消息,限制跨域。
Access-Control-Allow-xxx可以是以下值:1
2
3
4Access-Control-Allow-Origin
Access-Control-Allow-Headers
Access-Control-Allow-Methods
Access-Control-Max-Age //多长时间内,不需要再发预请求进行验证
下面以 Access-Control-Allow-Origin讲解。
Access-Control-Allow-Origin
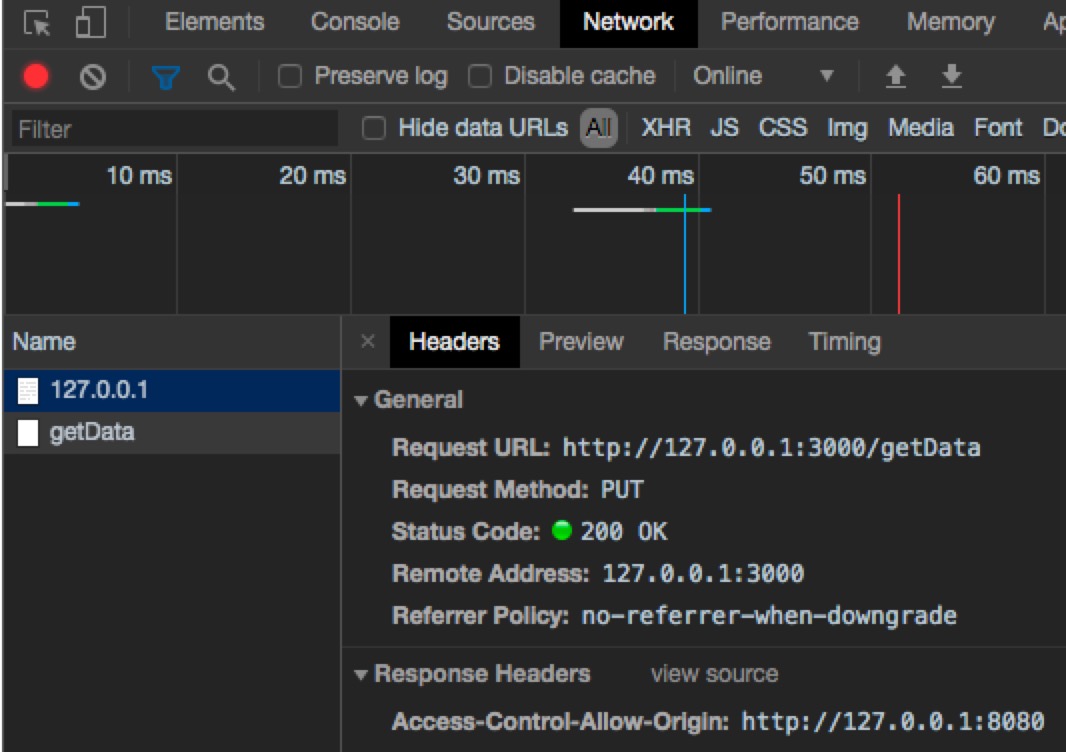
看请求是否跨域,主要是看后台的响应头否设置了 Access-Control-Allow-Origin;
Access-Control-Allow-Origin的值可以为 *,这样的话,任何域名下发的请求,响应数据都会允许获取到,是有一定危险的。1
'Access-Control-Allow-Origin': '*'
所以更可行的方法是设置一个具体值,1
2//允许host为http://127.0.0.1:8888的请求显示数据
'Access-Control-Allow-Origin': 'http://127.0.0.1:8888'
如果要允许多个host,可以设置多个值,这些都是很好做的。
Access-Control-Allow-xxx都可以在浏览器的响应头中看到: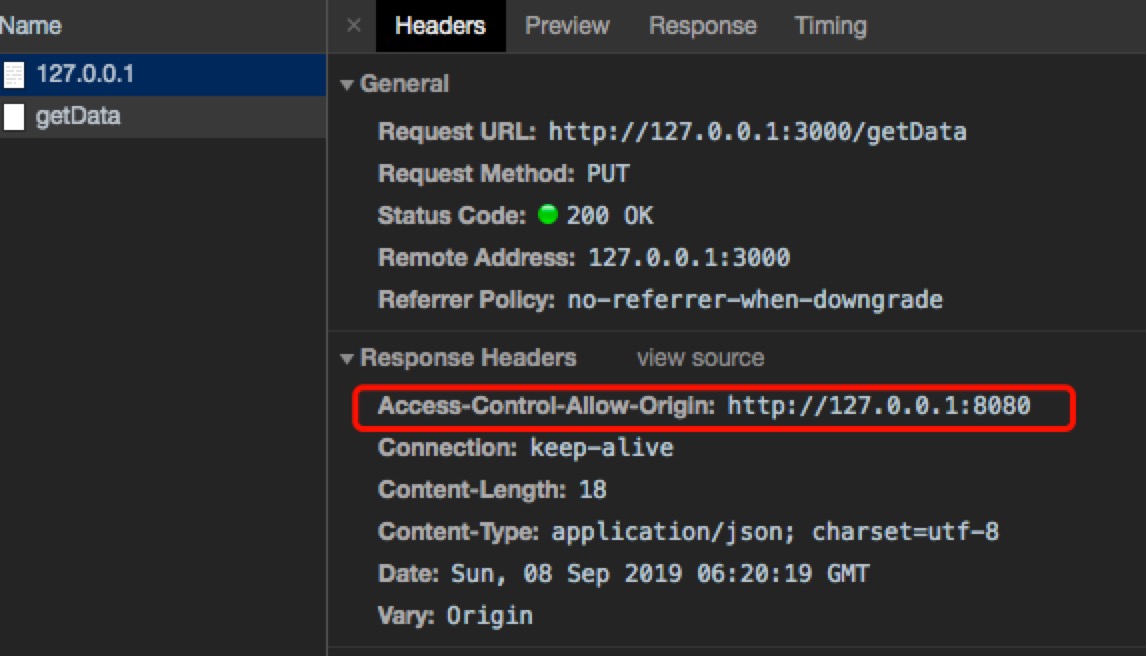
跨域解决方式
- 设置 Access-Control-Allow-Origin;
- jsonp
- 通过服务器转发请求
其他跨域解决方法
跨域时,除了要放开Access-Control-Allow-Origin,有时候,还会限制你的请求方法,请求头的设置,这个时候,
在后台就需要设置如下,进行approve: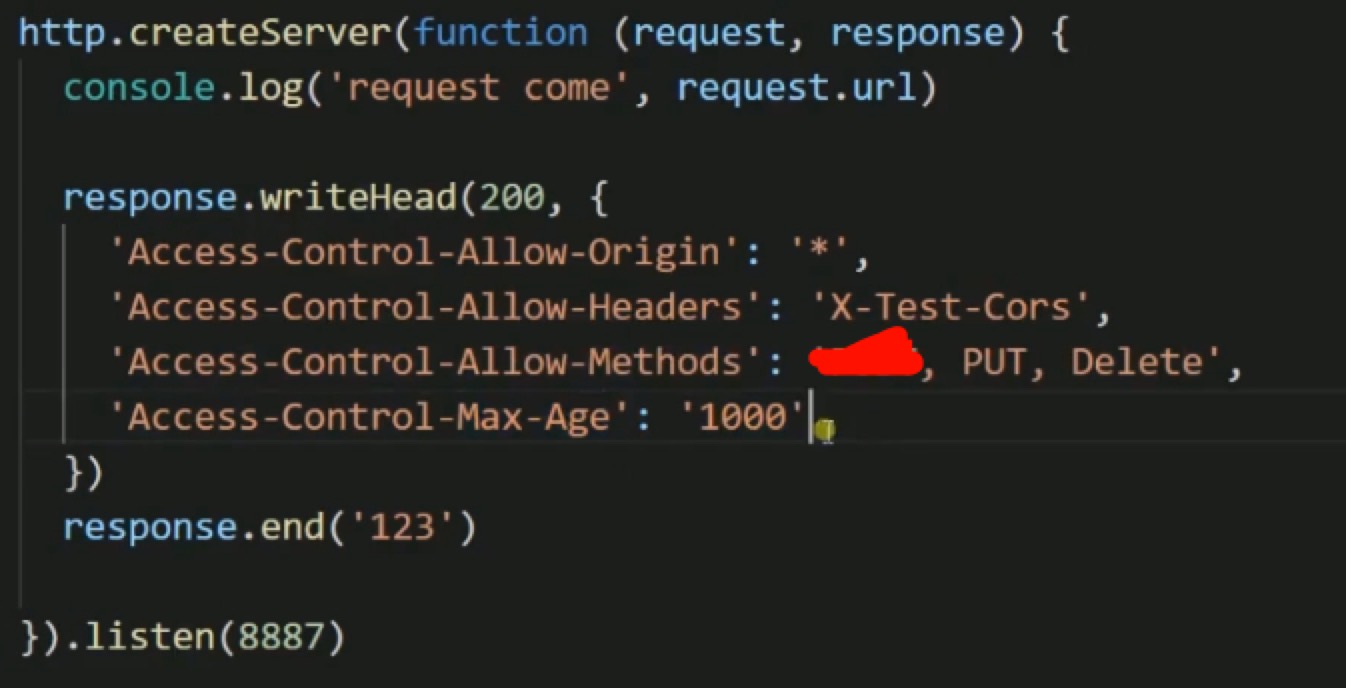
CORS预请求
在跨域请求时,还有一些其他限制,CORS预请求就是当中的一种:
跨域请求中,不需要预请求的方法:
- GET
- HEAD
- POST
跨域请求中,不需要预请求的content-Type: - text/plain
- multipart/form-data
- application/x-www-form-urlencoded
除了上述请求方法或content-type,当跨域时,浏览器都要进行预请求,
比如DELETE PUT 请求,
除以上设置外,如果你自定义header头,也会要求进行预请求,还有一些其他的预请求的限制,可以网上查阅。
下面展示一下预请求CORS预请求 与 OPTIONS method
cors预请求是通过OPTIONS method请求实现,在发送实际请求前,发一次OPTIONS method请求。 这是正常的post 跨域请求,不需要cors预请求
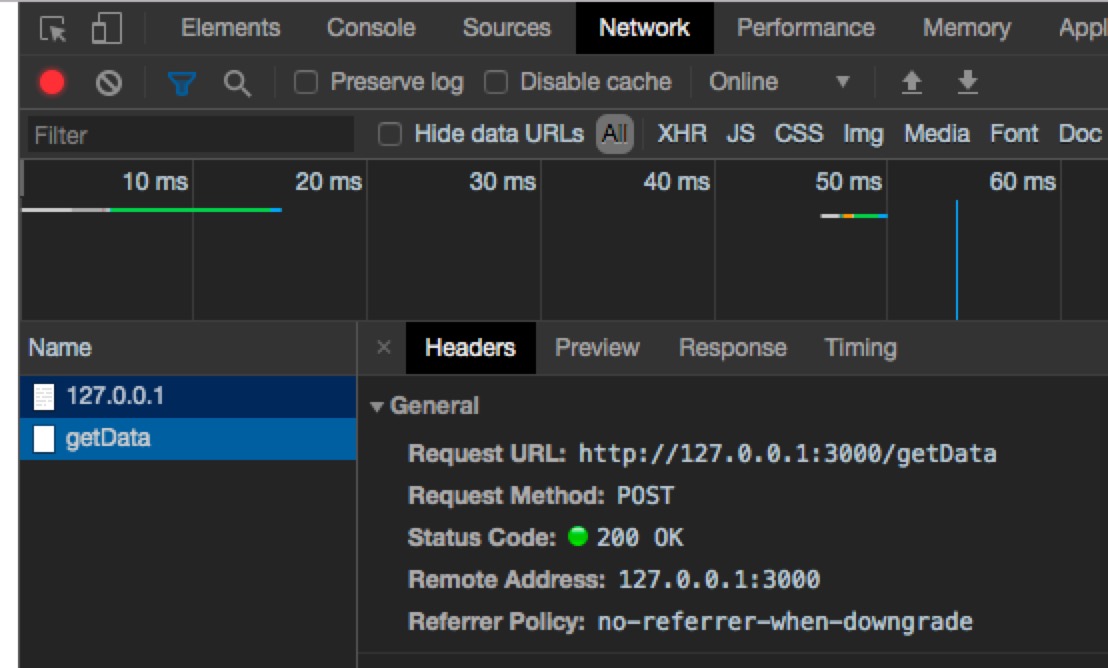
这是put 跨域请求,需要cors预请求
因此首先发一个method OPTIONS的请求,向服务器询问是否允许获取数据。
如果允许,则再发实际的put请求。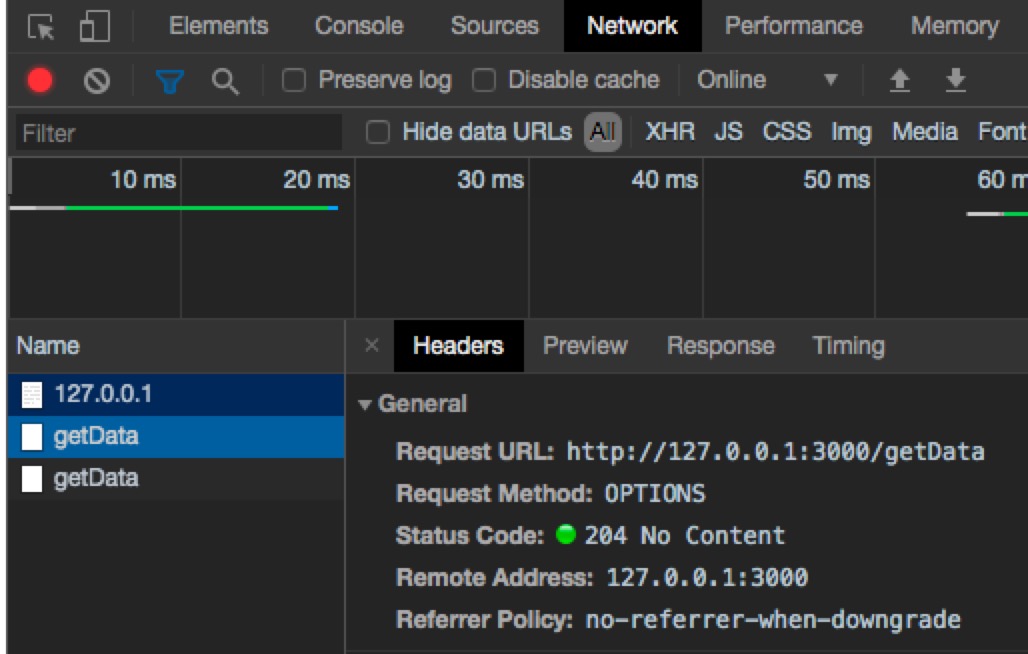
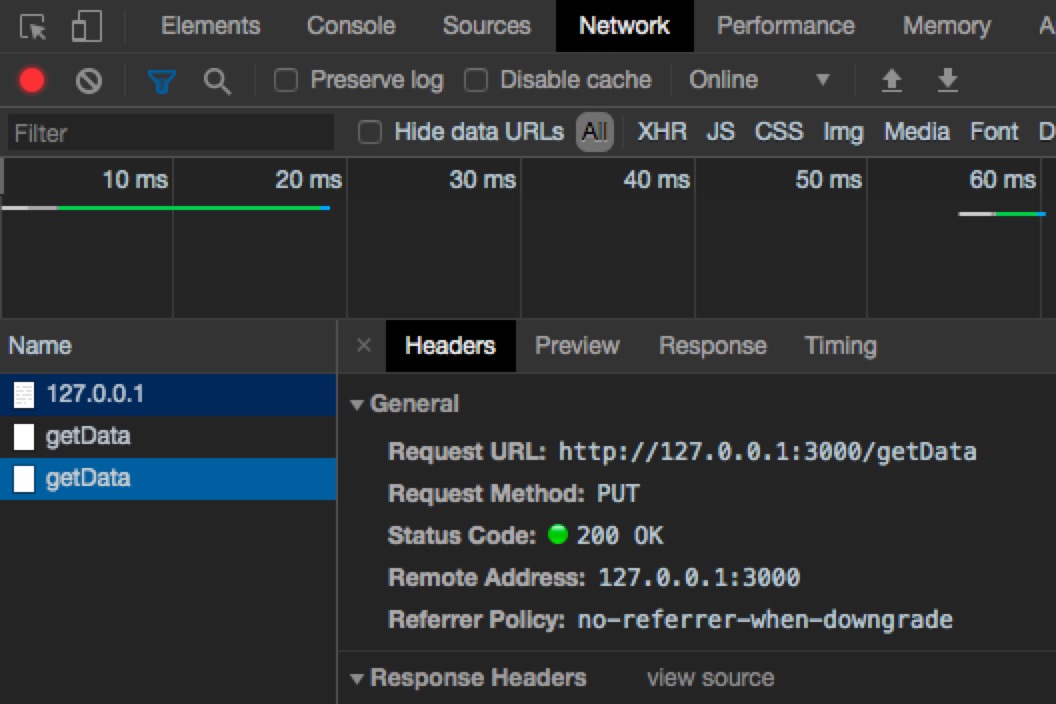
默认在一定时间内,再次发起跨域请求,不需再次发送options请求进行cors预请求
当上面请求正常后,立刻再次发起同样的put请求,浏览器不会再次重复需要进行预请求,当然这个时间是可以在服务器上配置的。
通过下面可以设置,如果不设置,就使用默认时间:1
Access-Control-Max-Age : 1000, //多长时间内,不需要再发预请求进行验证
CORS预请求 只 与 跨域有关
参考上面的讲解。
CORS预请求
参考《跨域 — CORS预请求》
Cache-control
Cache-control是服务端设置,告诉浏览器资源的缓存方式,可取的值:
- public 允许包含代理客户端的所有客户端进行缓存
- private 只允许发起请求的客户端进行缓存
- no-cache 允许客户端(使用)缓存资源,但需要到服务器上去验证
摘自
虽然在返回 304 的时候已经做了一次数据库查询,但是可以避免接下来更多的数据库查询,并且没有返回页面内容而只是一个 HTTP Header,从而大大的降低带宽的消耗,对于用户的感觉也是提高。 - no-store 不允许客户端缓存
其他指: - max-age 缓存过期时间
在koa 服务端设置如下:1
2
3
4
5
6app.use(async (ctx, next) => {
ctx.set('Cache-control', 'max-age=200, public'); //可以一次设置多个值
ctx.set('Content-Type', 'text/javascript');
ctx.set('Access-Control-Allow-Headers', 'Origin, X-Requested-With, Content-Type, Accept');
await next();
});
缓存试验
后端设置 max-age=20, public, 前端发起请求时,
第一次 响应码为 200,服务端能够接收到请求;
第二次(20秒内)响应码为 200(form disk cache),服务端没有接收到前端请求;
第三次(超过20秒)响应码为 200,请求会再次发送到服务端,服务端能够接收到请求;
1 | app.use(async (req, res, next) => { |
强制缓存与协商缓存
强制缓存,接口请求不会到达服务端;
协商缓存,接口请求到达服务端,返回304,告诉浏览器直接使用缓存,不需要返回body数据,节省了流量;
更多,参考《前端笔记-浏览器缓存》
也可(参考这篇博客:彻底理解浏览器的缓存机制](https://juejin.cn/post/6844903593275817998#heading-2)
浏览器读取缓存的过程
把本地缓存当成一个本地服务器
浏览器发起请求,首先读取本地缓存,然后读取代理缓存,如果都没有命中,就从服务器获取资源。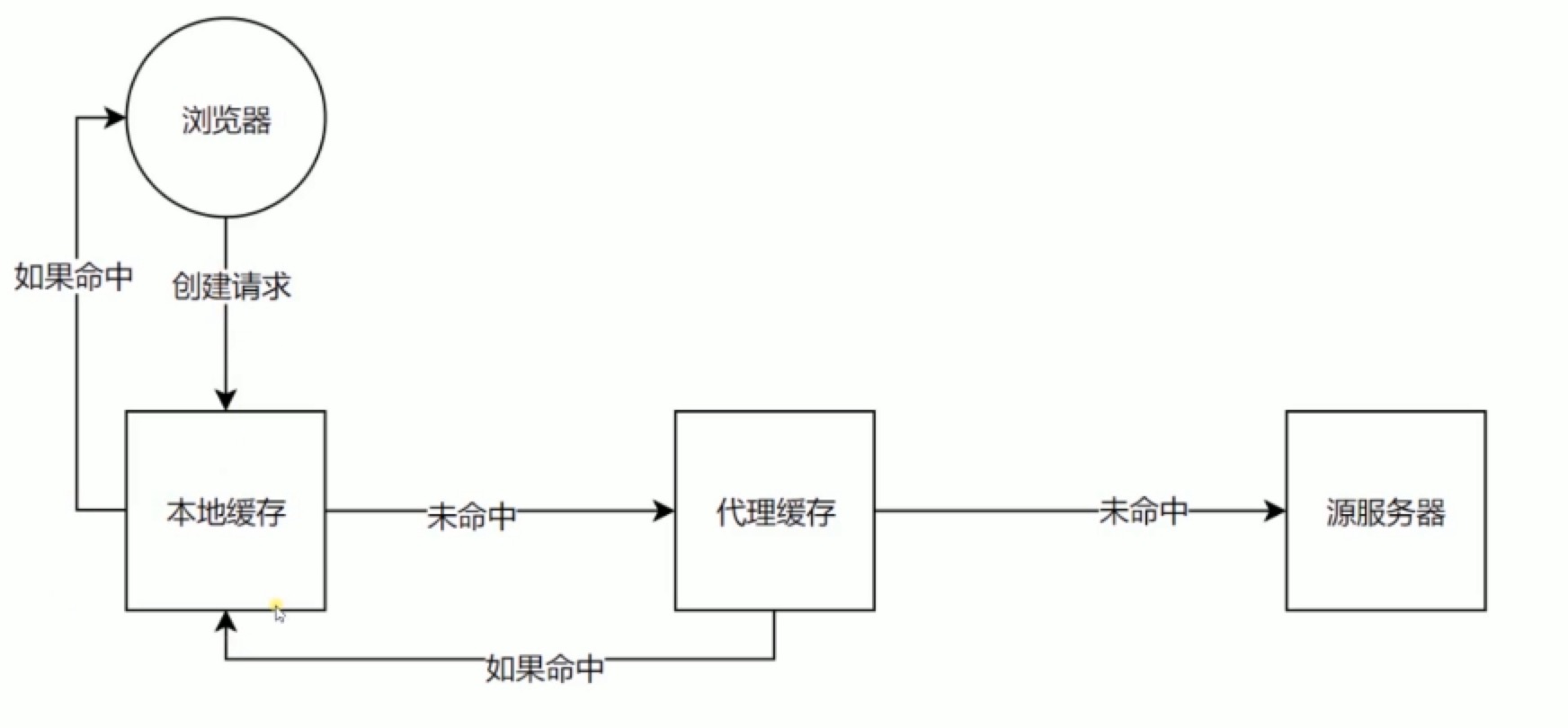
如上图知道,当设置缓存时,我们就好比多了一个本地服务端。
当再次发起请求时,请求直接发送到本地缓存服务器,而不是到后端服务器,所以,这也是为什么缓存请求,不会再次触发后端服务器程序执行的原因。
原来请求直接到了浏览器的缓存服务器上。
注意,有个代理缓存
参考上图。
POST请求无法被缓存
缓存一般只适用于那些不会更新服务端数据的请求。一般 Get 请求都是查找请求,不会对服务器资源数据造成修改,而 Post 请求一般都会对服务器数据造成修改,所以,一般会对 GEt 请求进行缓存,很少会对 Post 请求进行缓存。
缓存验证 - Last-Modified和Etag的使用
Last-Modified
上次修改时间,配合 if-modified-since或if-unmodified-since使用
Etag
数据签名,比Last-Modified更为严格的一种验证方式;
配合if-match或if-non-match使用;
后端配置(koa)
1 | //If-Modified-Since: 对应 Last-Modified值 |
浏览器表现行为
浏览器第一次请求时,没有缓存,状态吗为200,此时的请求头上是没有etag等信息的: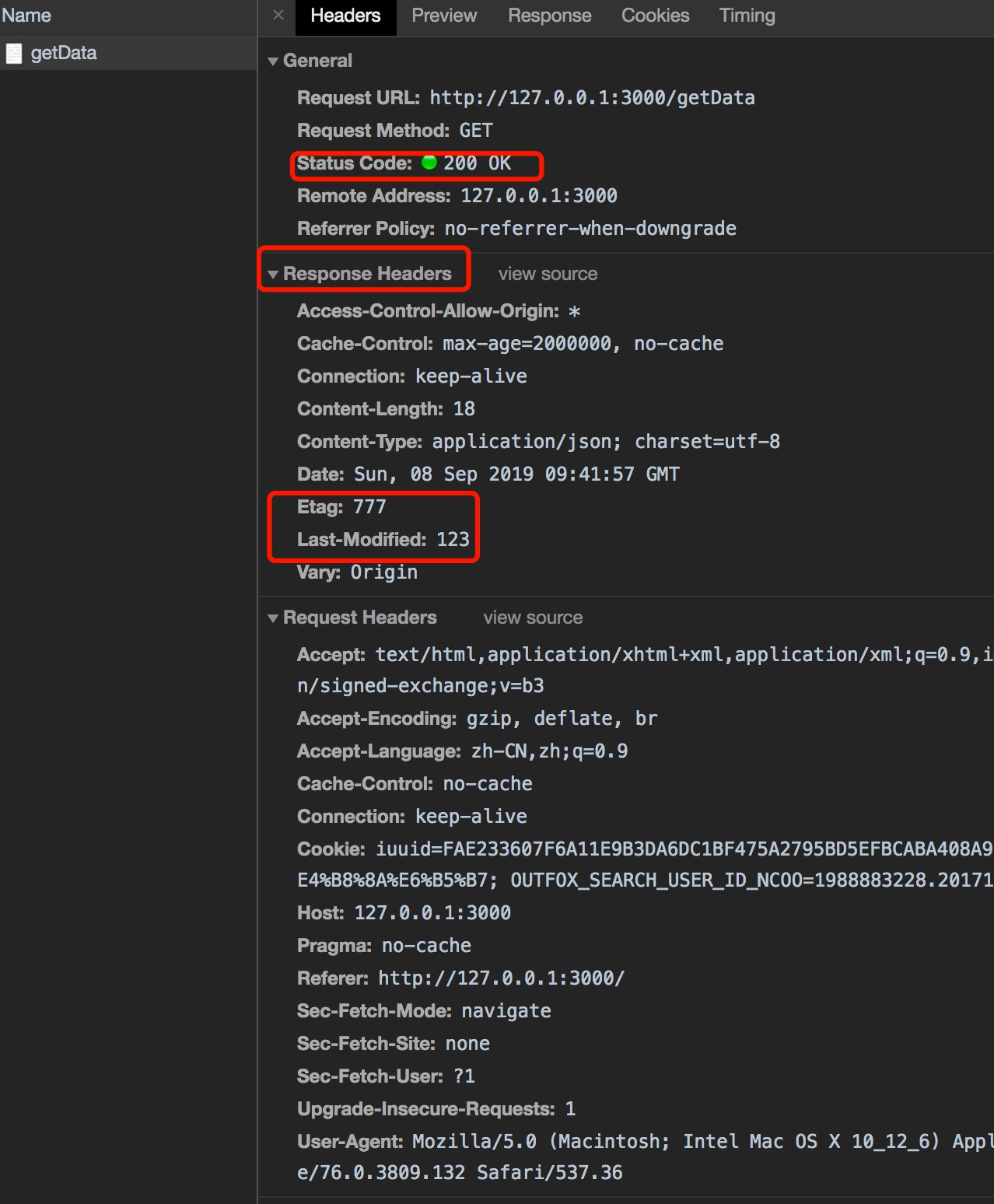
浏览器第一次请求完后,第二次发起请求,前台不用做任何设置,浏览器会自动将第一次请求返回给前台的 etag、Last-Modified等相关验证缓存的参数,发送给后台,后台对比验证后,通知前台使用缓存304.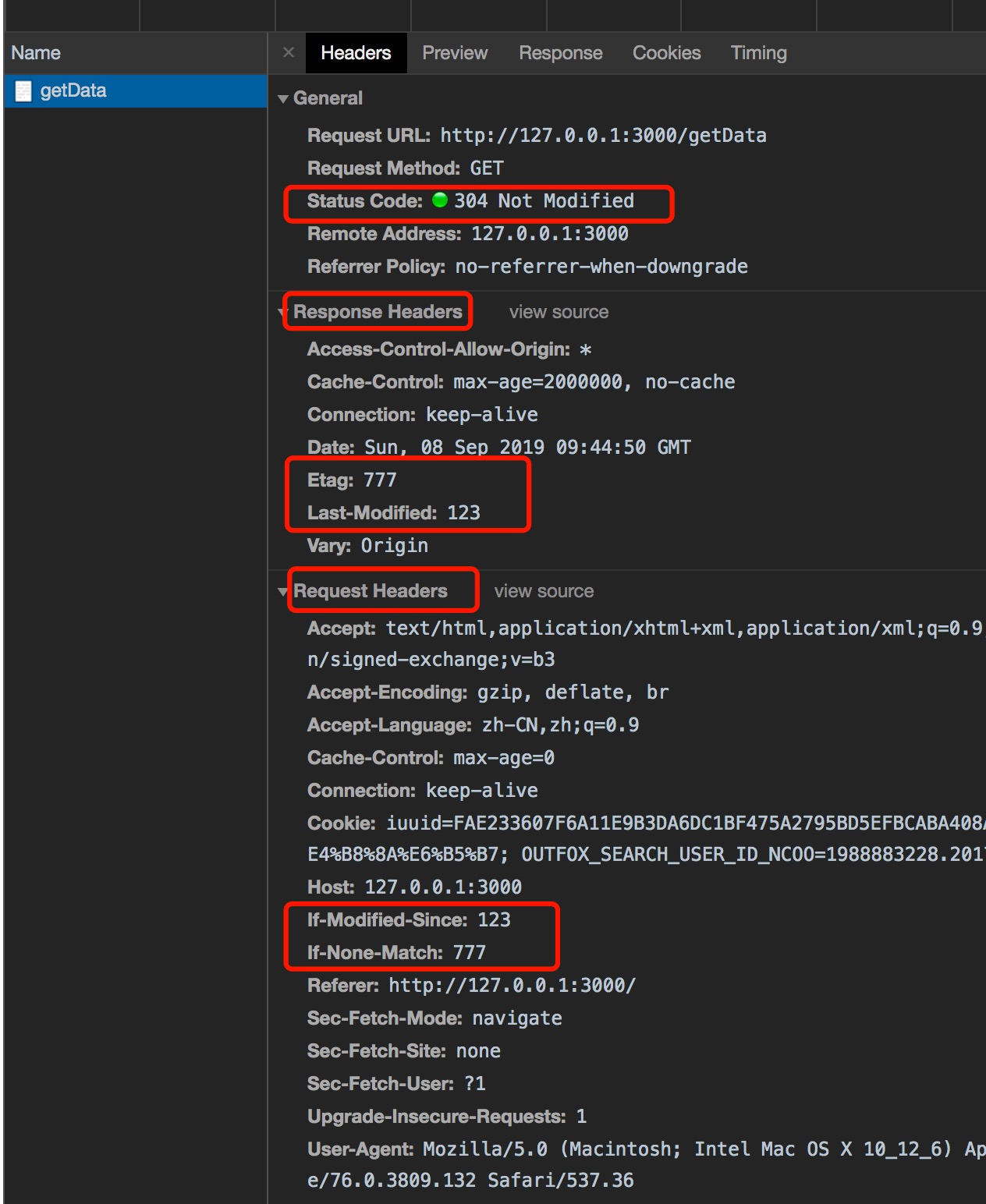
If-Modified-Since 对应 Last-Modified
当后台返回前台的响应头包含 Last-Modified时,浏览器下次请求时,请求头将包含Last-Modified信息,而这个信息换成If-Modified-Since来表示。
同理If-None-Match: 对应 etag值
If-None-Match 对应 etag
参考《If-Modified-Since 对应 Last-Modified》
浏览器会自动将etag等发给后台
浏览器自动将etag等自动传给后台,不需要前台做任何设置,这是浏览器的http协议机制决定的。
勾选控制台Disable cache
勾选浏览器控制台Disable cache时,浏览器将不会把etag等缓存验证相关的参数传给后台,因为不需要缓存了。
cookie
特点
- 通过set-cookie设置
- 下次请求会自动带上
- 键值对,可以设置多个
- 默认关闭浏览器失效
- 可通过设置cookie的有效期,让浏览器关闭后,cookie仍然有效
cookie有效期补充
没有设置失效时间(会话cookie);
(1)关闭浏览器;
(2)手动清除Cookie;设置时间;
(1)时间到了失效,即使关闭了浏览器也不会被清除,因为cookie信息被保存在了硬盘上,浏览器再次打开的时候就会读取硬盘上的数据,而且不同的浏览器之间是可以共享的;
(2)手动清除Cookie;
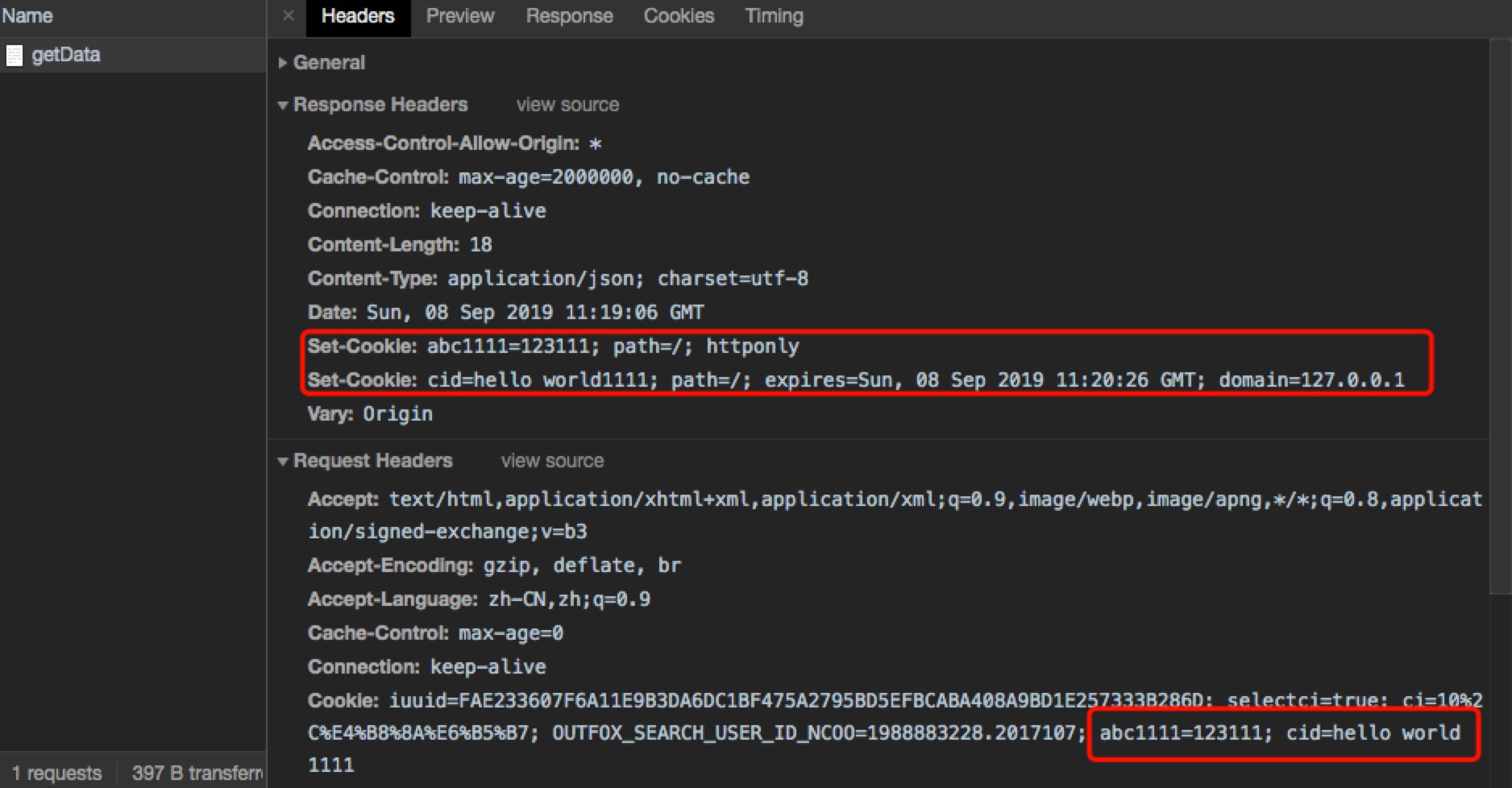
cookie概述
cookie是后台传给前台,前台再利用浏览器的cookie可以随http发回给后台的特性,对发回对cookie进行验证。
- 第一次向后台发起请求后,后台返回的响应头(response headers)包含了给浏览器设置cookie对功能(set-cookie)
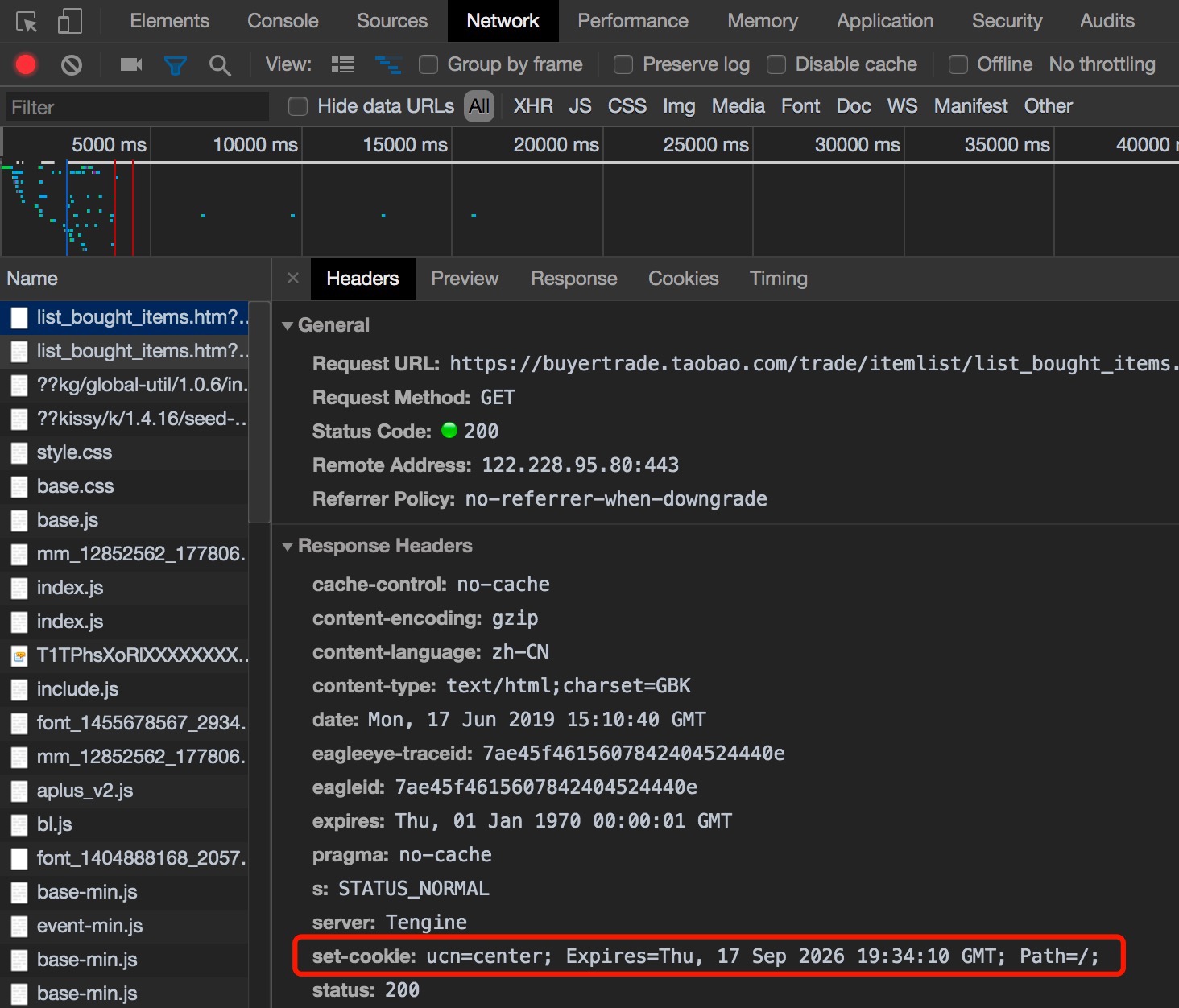
- 浏览器拿到cookie后,cookie有个特性,同域名下的cookie在发起请求时,都会发回给后台
- 后台通过比对session的cookie,进行超时、登陆等校验
补充一点cookie知识:
如下图 Expires/max-age 的值为 N/A是session永久有效的意思,另外一个每个cookie对应一个域名。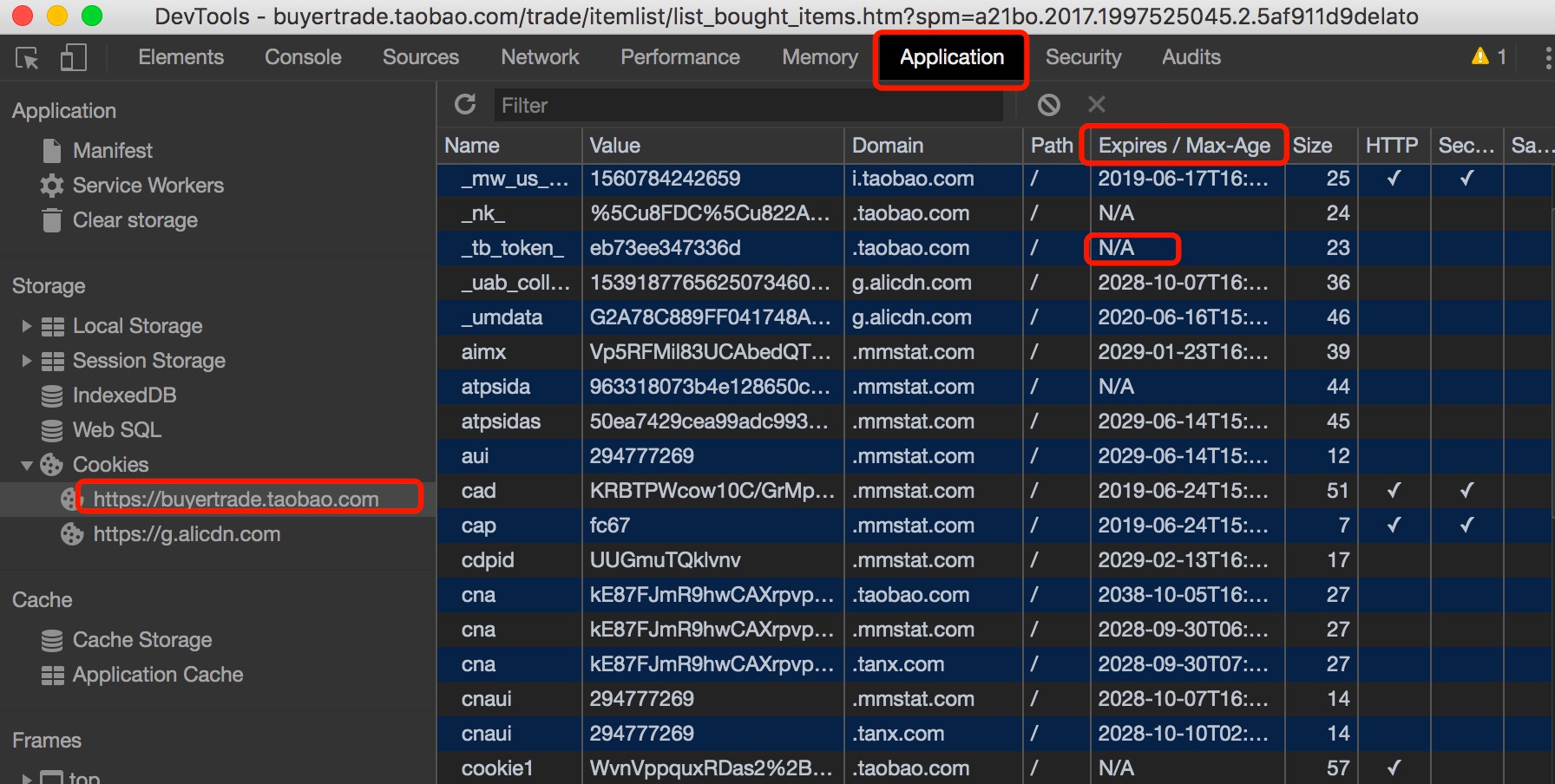
关于cookie设置
前后端都可以设置cookie,一次设置好,下次发请求,同域名下,cookie自动带上。
cookie与localStorage区别
cookie 主要给后端服务器用的,用于用户的验证,因为一旦后端服务器设置了cookie,比如在登陆成功后,设置好cookie,那么同域名下,再次发起请求时,cookie会自动带上,后台可以凭借这个cookie进行认证。
localStorage主要给前端使用。
cookie实现验证的原理
参考上面《cookie与localStorage区别》
koa端设置cookie
1 | if(ctx.url === '/getData'){ |
httpOnly 与 document.cookie
设置 httpOnly 为true时, 将无法通过document.cookie获取到该cookie。
控制台的Application
cookie可在控制台的 Application上查看,如果设置了cookie的maxAge,有效期过后,Application上将查不到此cookie。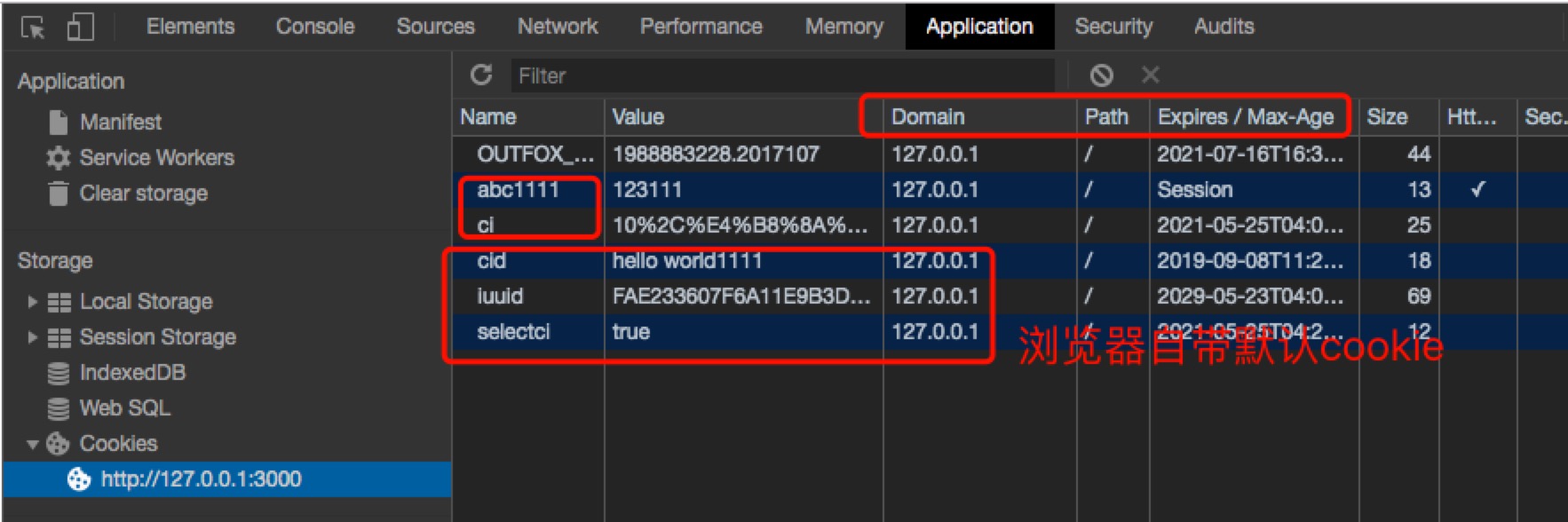
demo
这里是一个前后端一体的cookie demo,既实现了前端 又实现了后端 设置cookie。
demo
connect与HTTP长连接
长连接的意义
http请求是建立在tcp连接上的,一个tcp连接可发多个http连接;
如果每个http请求都要创建一个tcp连接,就相当影响性能,所以需要长连接,让多个http请求共用一个tcp连接。
后台设置长链接
1 | response.writeHead(200, { |
控制台查看connect-id
一个tcp连接会产生一个对应的connect-id作为标识。可通过connectid来看建立了多少个tcp连接。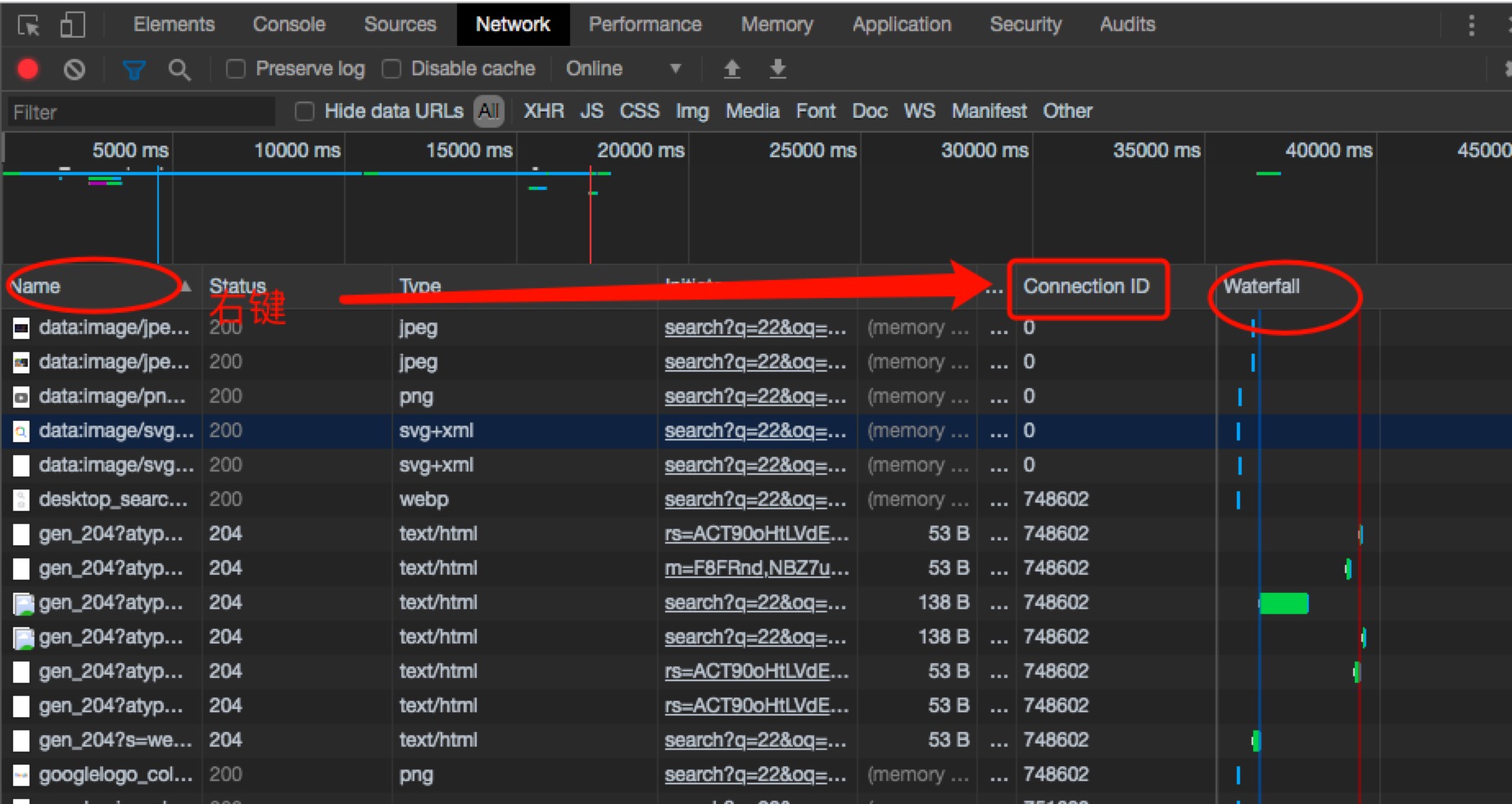
不同域名下的请求,connect-id不一样
在谷歌浏览器用的是http2,一个页面只有一个tcp连接,都是长链接,所以只有一个connectid,不过不同域名的资源需要再建一个tcp连接。
http1.1 最大可连接6个tcp
Content-Type (数据协商)
请求头的Content-Type
这里说都是 请求头上都 Content-Type,这个的作用主要是告诉服务器,请求参数要以什么的形式进行解析;
比如,一个包含图片等信息的form表单提交的时候,如果不设置Content-Type,服务器就无法正确解析form表单中的图片信息;
此时应该设置Content-Type:multipart/form-data,让服务器用流的来解析请求参数。
响应头的Content-Type
响应头的Content-Type,告诉前台数据类型,让前台按正确的方式解析响应数据。
小结
所以Content-Type其实就是前后台用来进行协商如何进行数据转换的。
重定向 (Redirect)
应用场景
重定向一般用于一个url地址已经被废弃,但为了兼容,需要将废弃地址重定向到新的url中。
所以它需要在服务端设置响应码为301,这样,浏览器的http机制就会记住,下次发同样请求时,就自动跳转到重定向的url地址。
需要服务端设置302
1 | if (request.url === '/') { |
服务端访问时效果如下,重定向可能会多一个location头: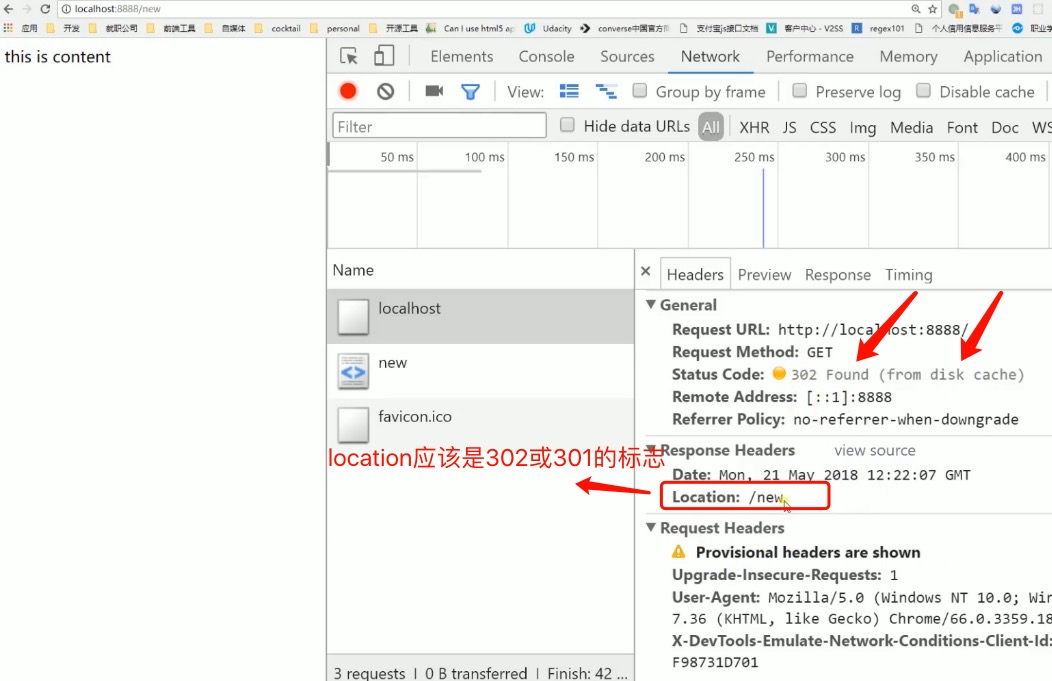
302 与 301
302是临时重定向;
301是永久重定向;
301 302的特殊特性
如上可知,301和302是 在后端设置好,同时浏览器也进行了配合,实现的一种行为。
浏览器读取到是302 301时,就会自动跳转到指定的重定向地址,这是浏览器自己会做的,应该也是http协议的一部分。
301后续请求都是读取缓存
注意的是,301是特殊的存在,如果不是必须,不要随意设置301,因为一旦设置301,浏览器将在第一次向服务器请求后,
后续将不再请求服务器,直接读取浏览器缓存。除非手动清楚浏览器缓存。
302没有此特性。
如何选择301或302
301因为浏览器在后续请求都读取浏览器缓存,所以一旦设置301,除非用户主动删除缓存,否则用户再也不会请求服务器,获取最新的跳转地址;
302每次后续请求会再次请求服务器,获取最新的跳转地址,所以服务器能够更好地控制客户端行为,获取最新跳转地址;
当然你也可以设置302的缓存有效期。
资源获取策略 Content-Security-Policy
服务端设置Content-Security-Policy,限制接口数据获取的方式,1
2
3
4
5response.writeHead(200, {
'Content-Type': 'text/html',
//限制浏览器只能通过https来发起请求
'Content-Security-Policy': 'script-src https'
})
前台接到服务器的返回后,读取Content-Security-Policy值,如果浏览器是通过非https发起的请求,那么改响应数据将不被显示,并且抛错提示资源获取策略异常
https
参考4-3
https主要通过公钥和私钥实现。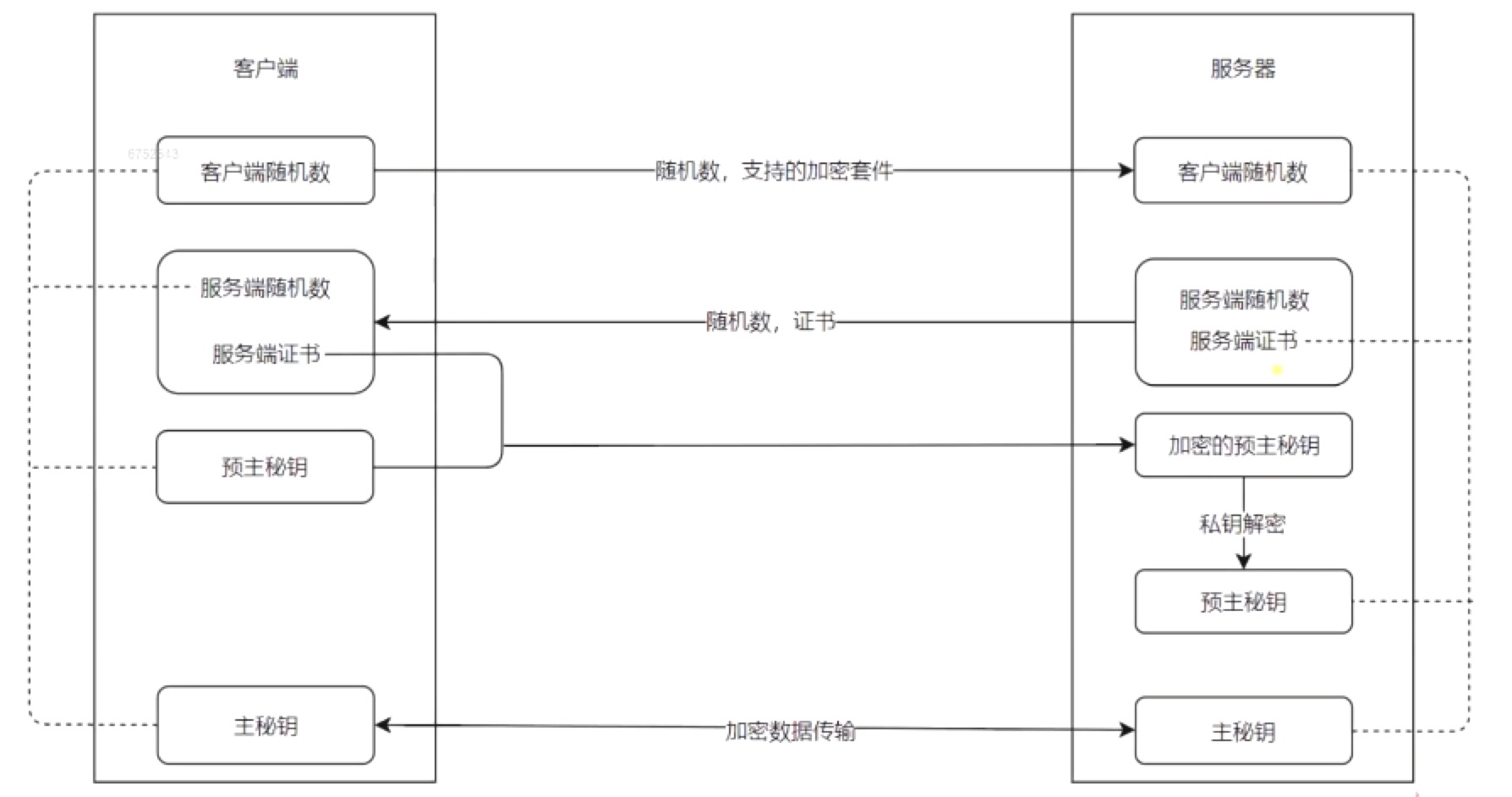
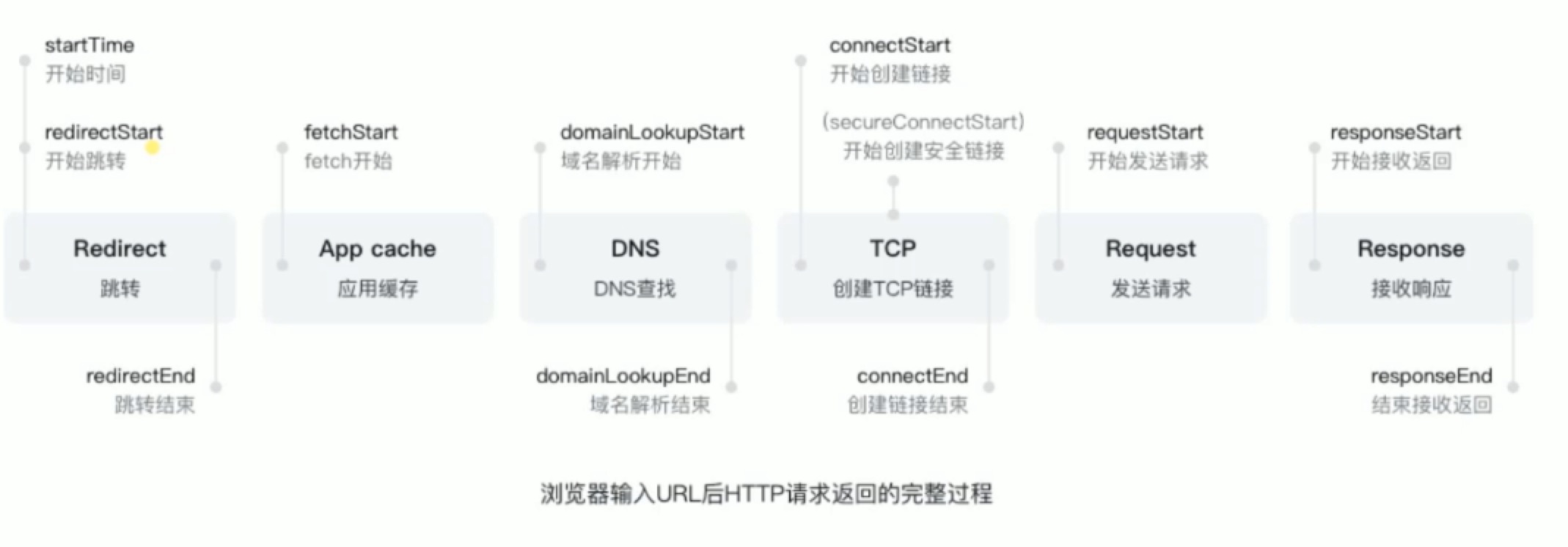
输入一个url后发生了什么